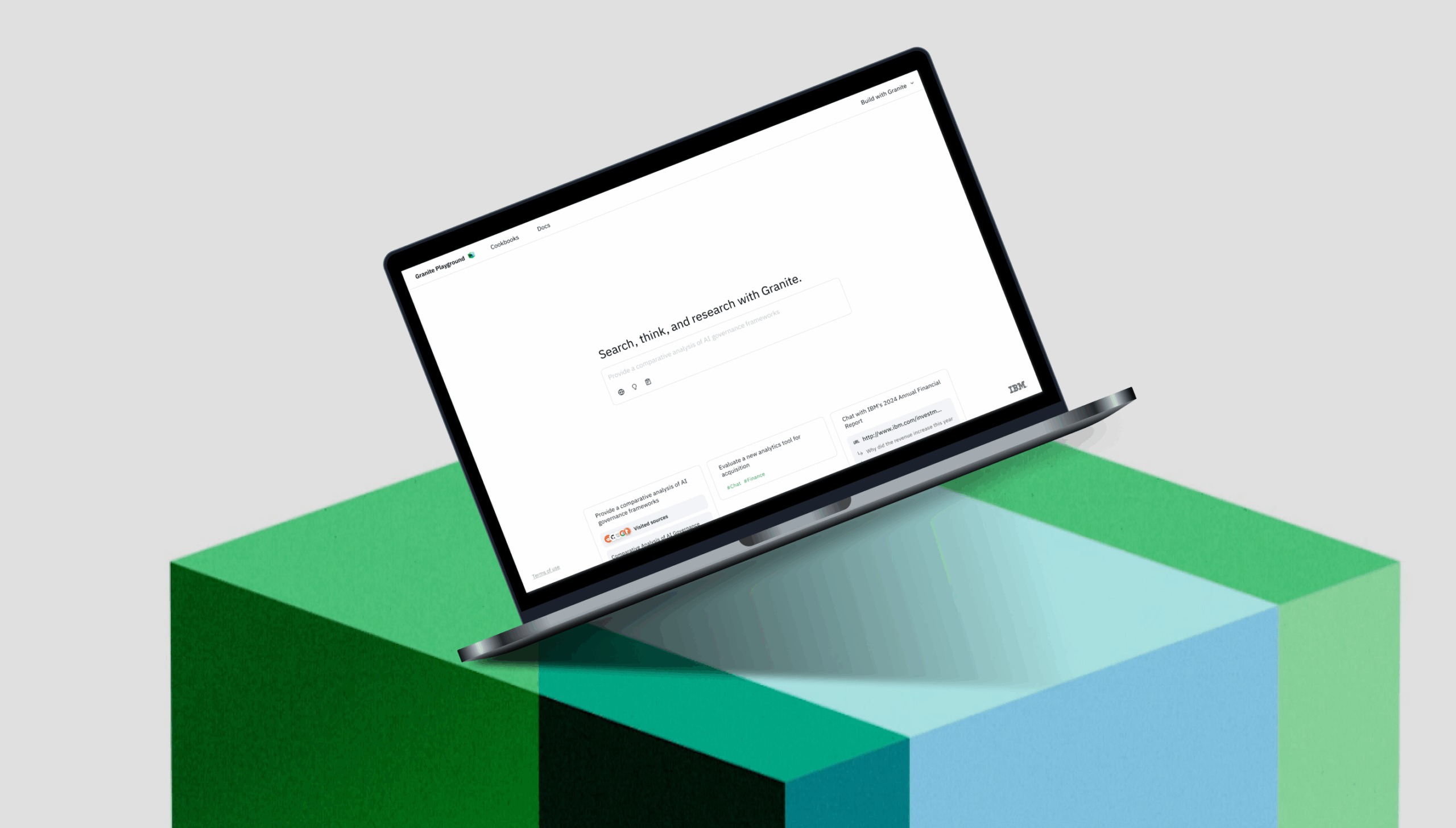
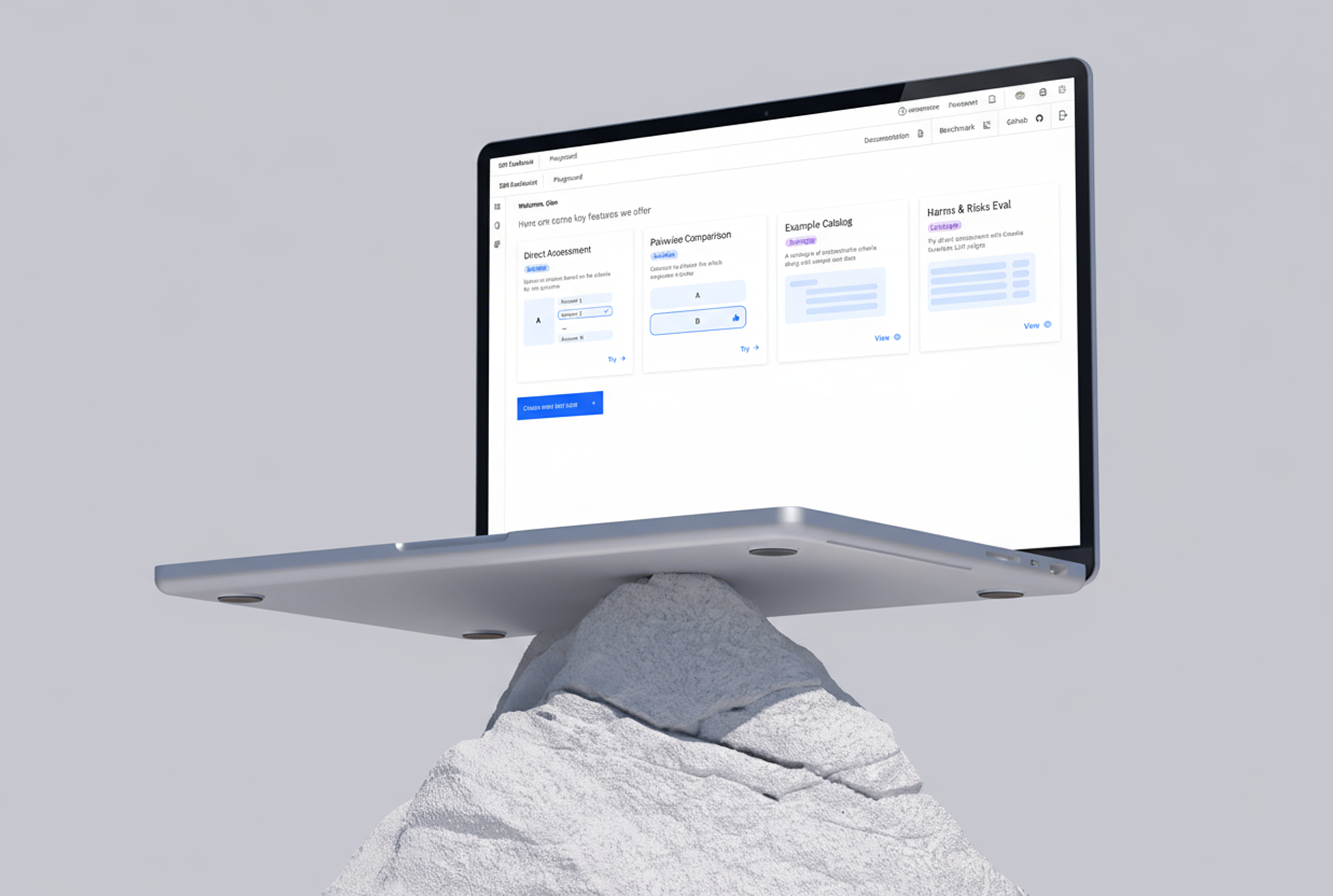
EvalAssist: Designing Human-AI Evaluation Workflows From Zero to One
How I transformed an ambiguous, emerging opportunity into a trusted evaluation product that inspired users and unlocked new business directions.
Leveraged multiple AI tools to create this video in two weeks, from concept to final production.
To comply with my non-disclosure agreement, I have omitted and obfuscated confidential information in this case study. Information in this case study is my own and does not necessarily reflect the views of IBM.
My Role & Scope
UIUX Design Lead (2023-Now)
- Identify Incubation Opportunities
- Define Product Strategy
- Conduct Exploratory Research
- Design and Prototype UI/UX
- Perform User Research and Iterative Improvements
- Collaborate Across Teams & Departments
Team
Core Team (IBM Research HCAI)
- 1 UIUX Designer
- 3 HCI Researchers
- 4 AI Research Engineers
- 1 Front-end Engineer
- 2 Research Project Lead
Collaborators
- IBM Watson X Governance Product Design Team
- IBM Research Granite Guardian Model Development Research Team
- Georgia Tech HCI Master Program
Impacts
Successful Product Incubation
- The EvalAssist tool is now offered as part of the IBM Watsonx Governance SDK.
- Its design was adopted by the Granite Guardian model as a custom LLM judge to showcase risk evaluation capabilities, resulting in over 10,000 model downloads.
Top-Level Department Recognitions
- O-Level award for design impact on IBM Granite Guardian foundation model.
- A-Level award for successful open-sourcing of EvalAssist and research excellence, with 4 top-conference publications (first author on 1).
Project Context
In 2023, following the release of ChatGPT, the AI landscape shifted almost overnight. Organizations raced to adopt foundation models, yet lacked reliable, repeatable ways to evaluate them.
Our team was tasked with exploring innovation opportunities across the end-to-end LLM solution development process—work that would inform org-level strategic planning in an increasingly competitive space.
At the time, no clear product existed, no standard workflow existed—only a widening gap and a rapidly escalating need.
Starting Question:
Where are the meaningful innovation opportunities in model onboarding especially model adoption?
Impact Measurement
How Success Is Defined in IBM Research
In this rapidly evolving AI landscape, IBM Research operates as both an innovation hub and an acceleration engine. Unlike traditional research timelines that look a decade ahead, today’s generative AI ecosystem moves at industry speed. Our mandate is to identify the most urgent needs, rapidly prototype solutions, and help IBM not only catch up—but lead.
Within this context, success for our Human-Centered AI team is measured in two complementary ways:
1. Advancing Human-Centered Innovation
We are evaluated on our ability to propose novel, high-value solutions to emerging AI interaction challenges.
This impact is validated through:
- Publications at top HCI and AI conferences
Patents that formalize innovative design and technical contributions
These signals demonstrate that our work pushes the boundaries of trustworthy AI and establishes new patterns for the field.
2. Driving Product & Organizational Acceleration
Because our research directly supports IBM’s AI product ecosystem, we’re also measured by how effectively our work:
- Informs product strategy and decision-making
- Integrates into active product roadmap
- Seeds or inspires new product capabilities
This dual lens—scientific innovation + product impact—defines how we evaluate the success of 0→1 exploration efforts like EvalAssist.
For additional context, you can also refer to my talks at IBM Design Festival 2021, where my colleague and I shared insights on:
My 0-1 Design Process
From the initial ambiguity of a problem space, I anchor the process in user research to uncover needs and opportunities. I then shape and test solution directions, iterating from rough concepts to a focused MVP and ultimately a polished, high-confidence product direction. While I represent the process as a funnel to illustrate progressive refinement, it remains highly iterative, with continuous user research, testing, idea iteration, and feedback loops informing every stage.

To dive deeper into my design process, check out our Medium article on how we coached AI technology teams to drive user-centered improvements.
Exploratory User Research
Turning Ambiguity Into Direction: My First Step
To transform this abstract opportunity, I partnered with our HCI researcher to conduct 28 interviews with 38 practitioners who have adopted LLMs in their project development. We mapped their real evaluation behaviors into a conceptual diagram of the model onboarding journey to inform organizational-level strategic planning
Participants


Research outcome
The conceptual diagram summarized our research findings and served as a validation artifact. It was iterated based on user interview insights, helping refine the end-to-end workflow and key decision points. Interview pain points were distilled into opportunity areas that shaped our strategic planning and guided meaningful solution directions.


Strategy Impact
Three workstreams were formed based on the opportunities uncovered through this exploratory UX research, where I served as the lead designer



Key Findings
Here are top 3 key findings related to LLM-as-a judge workstream:
1. Evaluation was the #1 bottleneck in model adoption.
Teams either:
– Relied on external benchmarks that didn’t fit their use cases
– Compared models using unstandardized prompts
– Or avoided evaluation entirely—leading to poor model choices and wasted time
2. Evaluators needed to test 100+ prompt–model combinations—fast.
However the process was manual, scattered, and difficult to interpret. Many literally copied outputs into spreadsheets for side-by-side review.
3. LLM-as-judge workflows were promising but lacked trust.
Users repeatedly asked:
“How do I trust the judge model?”
“How do I define metrics that fit my domain?”
“How do I understand or audit judge decisions?”
To explore my UX research findings on Model Evaluation, see the first part of our presentation from the IBM Spark Design Festival 2023.
Reframing the problem
How might we leverage LLMs to evaluate generated model outputs in a way that is effective, trustworthy, and aligned with user needs to save cost and improve productivity?
Design Exploration
Starting as a side project in December 2023 with a small cross-disciplinary collaboration, our exploration of human-LLM judge workflows led to two top conference publications (IUI and ACL 2024) and evolved into EvalAssist—shaped by design recommendations grounded in user research. Now a formal IBM Research initiative with nine core team members and three active collaboration workstreams, I lead UI/UX design to continually learn from AI and user research to drive innovation and adoption.

State of Art Review

MVP Key Value Proposition Refine
During the design exploration, we broke down the problem space into three key areas of value: better workflow, better metrics, and better data.
“With limited resources and an entirely new problem space, we needed sharp focus.”
To move from exploration to execution, I guided the team in defining an MVP around an automated evaluation workflow—a lean but high-impact slice of the experience that could:
- Demonstrate clear user value
- Validate the feasibility of LLM-assisted judging
- Build trust through transparent human-in-the-loop interactions
- Secure leadership confidence and investment
With these criteria in mind, we focused the MVP on automated evaluation complemented by structured human inspection. This approach became the anchor for our design decisions, reducing development time from weeks to days while still proving the core value of the technology.



Key Design Decisions

1. Minimize the Dashboard to Highlight the Primary Call to Action
We simplified the dashboard so the experience centers around a single, high-priority action: create an evaluation. This reduces noise, lowers decision fatigue, and helps users move quickly into the workflow where value is generated.
2. Prioritize Outcomes Over Configuration
We shifted from a complex, multi-criteria setup to a streamlined, single-criteria workflow that reduces cognitive load. Instead of requiring users to prepare custom datasets, we introduced preloaded datasets with prompt-driven generation, enabling fast onboarding while still supporting diverse outputs.
3. Streamline the Automation Flow to Reduce Manual Effort
Evaluation setup was reimagined as a simple, automated flow. Users no longer need to manage frequent checkpoints—instead, they initiate an evaluation once and review results afterward. Human oversight occurs after the fact, supported by pairwise comparison as the core judging mechanism for clarity and reliability.
4. Make Human Oversight Intentional, Blind, and Auditable
To strengthen trustworthiness, human reviewers assess outputs without seeing model names, ensuring unbiased judgments. Agreement rates are automatically calculated, transforming human input into a reliable and auditable signal that informs final evaluation outcomes.
5. Provide Transparent, Granular Outputs and Judge Rationales
Each pairwise comparison yields detailed results that are aggregated into clear win rates. We also expose LLM judge rationales, giving users insight into the reasoning behind each decision. This transparency supports better debugging, accountability, and a deeper understanding of model behavior.


For a deeper dive into the design research I led, refer to our ACM DIS 2024 publication


Information Architecture
We strategically expanded our work from the initial MVP into a more comprehensive evaluation sandbox platform—with categorized examples, more robust evaluator methods, and improved evaluation workflows—through deep collaboration with a range of research partners:
- Granite Guardian team — We built a library of risk-specific test cases (criteria and data) that helps users evaluate their use cases with a stronger focus on risk-related concerns. This also enables Granite Guardian to better showcase their capabilities and increases trust and adoption of IBM models as custom evaluator models.
- AI researchers — We benchmark various evaluation approaches so users can more easily select the method that best fits their use cases.
- AI research interns — We explore new algorithms to enhance the transparency of evaluation results, including uncertainty scores and explanatory insights.
- Georgia Tech HCI master’s students — We co-design improved ways to represent large-scale evaluation outputs, making them easier for users to understand and act on.
- AI researchers (synthetic data) — We generate synthetic data to surface edge cases, helping users refine their criteria definitions for broader coverage and stronger robustness.
- WatsonX and RITS API integration — We deepen integration with the IBM WatsonX product through its RITS APIs, enabling users to easily bring in different models for experimentation, compare options, and choose the best model for their tasks.

Key design feature highlights
Flexible Modalities
Research Finding:
User research with over 700 internal users revealed that evaluation preferences vary by task type: users preferred direct assessment when they wanted more control, and pairwise comparison when evaluating more subjective aspects.
Design solution
We designed the system to support both direct assessment and pairwise comparison, giving users the flexibility to choose the method that best fits their specific use case.


Custom Metrics
Research Finding:
In interviews with 8 data scientists and developers, users expressed a strong need for structured yet customizable evaluation templates. As one participant noted:
“A freeform text box is too simple. I would love there to be templates that I can utilize. And at the very least, be able to just edit so that I can get into my use case.” — P7
Design solution
We introduced a library of customizable criteria templates, enabling users to iteratively design and refine evaluation metrics through an interactive interface. Templates can be exported in a standardized JSON format, making them easy to reuse and integrate into different workflows.
Specialized Evaluator
Research Finding:
We conducted benchmark testing with the latest LLM evaluator models and developed a customized prompt pipeline optimized for the best-performing models.
Design solution
The system integrates a range of general and specialized LLM judges—including IBM Granite Guardian, Llama 3, Mixtral, Prometheus 2, and GPT-4—using a chained prompting strategy to ensure consistent, high-quality evaluations across diverse tasks.


Robust Eval Data
Research Finding:
User research with over 700 internal users revealed a common tendency to overfit evaluation criteria based on a narrow set of responses. This underscored the need for broader, more diverse datasets to help users refine their evaluations more effectively.
Design solution
The system leverages LLMs to generate diverse synthetic datasets, simulating a range of personas and domain contexts. This helps users uncover blind spots and improve the robustness and generalizability of their evaluation criteria.
Trustworthy Results
Research Finding:
In interviews with 8 data scientists and developers, users emphasized the importance of transparency in the evaluation process to build trust. One participant shared:
“So I definitely want, as we discussed earlier, a lot of transparency in exactly what is being sent to the models to generate the responses and then what is then being sent to the LLM as a judge.” — P2
Design solution
The system provides built-in transparency tools, enabling users to inspect the full evaluation pipeline. Features include trustworthiness metrics such as positional bias detection, certainty scores, and model-generated explanations to promote confidence in the evaluation outcomes.

Video Demo
To showcase EvalAssist’s use case, I collaborated with the team to define the story and used AI-assisted tools to produce the video. Keyframes were generated with AI image tools, animated via KlingAI and edited with Adobe Premiere, with voiceovers from ElevenLabs. Starting from a simple storyboard, this workflow allowed rapid, creative production while clearly communicating the demo’s narrative and EvalAssist’s real-world application.
Outcome
This tool has been in internal use since May 2024 and now open source for public usage. The design exploration has continuously supported research innovations that highlight both the scientific leadership in this area and the product’s impact and adoption—enabled by active cross-team and cross-department collaboration. This work was honored with IBM Research’s highest achievement recognition.
Top Conference Publications & Demos
5
- Evalullm: Llm assisted evaluation of generative outputs
- Human-centered design recommendations for llm-as-a-judge
- Black-box Uncertainty Quantification Method for LLM-as-a-Judge
- EvalAssist: LLM-as-a-judge simplified
- Designing Scalable and Transparent Interfaces for Multi-Criteria Evaluation of LLM Outputs
Adoptions & Incubations
5
- Offered as part of the IBM Watsonx Governance SDK.
- Design adopted by the Granite Guardian model as a custom LLM judge to showcase risk evaluation capabilities, resulting in over 10K model downloads.
- integrated with the UNITEX toolkit, has been open-sourced to support broader innovation and was highlighted in an IBM Research post
- Design components contributing to IBM Carbon for AI Design System
- Actively used by more than 100 IBMers across labs and by IBM Consultants to experiment and develop solutions for clients
Feedbacks
Reflections

What went well
Rapid MVPs Through Cross-Functional Design Jams
I feel fortunate to be part of an AI research team that deeply values cross-functional collaboration. Every Friday, a small group of us—designers, engineers, and researchers—meet to discuss emerging research and recent innovations. These informal sessions often turn into fast-paced brainstorming workshops, where I sketch out wireframes and early ideas while my teammates help shape and scope them into lean MVPs we can prototype and test within days. This collaborative, hands-on approach has proven far more effective than working in silos and has become a vital part of how we move ideas forward quickly.

What could be better
Staying Lean in a Rapidly Evolving LLM Landscape
Although we started with focused MVPs, the scope often expanded as new ideas and features emerged. The LLM space evolves so quickly that it’s a constant challenge to keep up with the latest innovations, research, and product developments. While we were busy building and experimenting, we sometimes lacked the structure to pause and evaluate whether we were building on top of the most recent learnings in the field. In hindsight, we could have benefited from a more intentional rhythm of research review and reflection to stay aligned with the fast-moving landscape.

Food for thought
Designing at Speed: Fast Prototyping for Clarity, Validation, and Risk Reduction
One key takeaway is the importance of prototyping quickly—not just to test ideas with users early, but to communicate clearly across disciplines. Turning rough concepts into fast, tangible prototypes helped align our team faster and avoid misunderstandings. It also opened the door for early feedback and more confident iteration. My recommendation for future projects is to make rapid prototyping a regular part of the process—it’s a simple but powerful way to stay focused, collaborative, and user-centered.
Acknowledgments
I’m deeply grateful to my manager for fostering an environment where exploration, fast iteration, and cross-functional collaboration are truly valued. Special thanks as well to my brilliant colleagues in design, engineering, and research—your insights, feedback, and energy made this work not only possible, but genuinely rewarding. Collaborating with such a thoughtful and talented team has been one of the most inspiring parts of this project.
MY PORTFOLIO
- All
- Case Study
- AI
- AR/VR
- Other